Few can match the British Government when it comes to belligerent secrecy. Under the shameful Official Secrets Act, not only is practically everything a state secret, but there are no public interest exceptions that allow the whistle to be blown on corrupt, deceitful or inept politicians, for example.
One person suffering mightily at the hands of the British Government and its attempts to stifle the truth is Craig Murray. Until recently, he was British Ambassador to Uzbekistan. But his growing distaste for the current Uzbeki regime, and the for the British Government's complicity in obtaining intelligence extracted by foreign torturers (specifically Uzbeki ones), has led him to become one of both governments' most articulate and implacable critics.
Of course the British Government hardly wants the information he has been privy to out in the open, and it has been steadily applying pressure to keep it secret. A few years back, it would have succeeded. But in these days of the Internet it has already lost that battle.
Murray has posted some deeply incriminating documents to his blog (read them here, and weep at the Machiavellian duplicitousness and moral degradation of the UK Government). Just as importantly, he has asked other bloggers to copy and publish them.
Heaven knows that I have no time for facile boosterism that sees every blogger - all 24 million of them - as a potential William Shakespeare. But never mind the quality, feel the width: their astonishing numbers, and their continuing growth, make them potentially powerful weapons in the fight against closed minds in general, and official secrecy in particular. As this useful page shows, the Uzbekistan genie is out of the proverbial bottle, and nothing the UK Government can do is going to put it back.
30 December 2005
29 December 2005
Open Beats Patent
One of the themes these postings hope to explore is the way in which openness, in all its forms, can function as an antidote to the worst excesses of the current system of intellectual property. In particular, freely-available knowledge is one way to mitigate the patent system, which has problems all around the world, but is in a particularly flawed state in the US.
As an example, BBC News has an interesting story about how India is creating a database of materials relating to traditional medicine in order to stymie attempts by companies (particularly US ones) to patent this age-old knowledge.
What is particularly galling is that patenting derives its name from the requirement to make a novel and undescribed invention "patent"; but in the case of knowledge that has been available to a society for centuries, the idea that someone (particularly an outsider to this society) who makes something already known "patent" in this way suddenly gains exclusive rights to a hitherto common good is profoundly offensive to anyone with any respect for ethics - or logic.
As an example, BBC News has an interesting story about how India is creating a database of materials relating to traditional medicine in order to stymie attempts by companies (particularly US ones) to patent this age-old knowledge.
What is particularly galling is that patenting derives its name from the requirement to make a novel and undescribed invention "patent"; but in the case of knowledge that has been available to a society for centuries, the idea that someone (particularly an outsider to this society) who makes something already known "patent" in this way suddenly gains exclusive rights to a hitherto common good is profoundly offensive to anyone with any respect for ethics - or logic.
27 December 2005
Dell the Bellwether
Whatever your views of Dell, it's an important company in the computer world. So the news that it is now installing Firefox as standard alongside Internet Explorer on machines sold in the UK is significant. Dell is nothing if not a bellwether, and where bellwethers lead, the flock generally follows.
26 December 2005
Open Access vs. Intelligent Design
Michael Eisen, a co-founder of the wonderful Public Library of Science project - a series of journals that make all of their content freely available - and one of the keenest exponents of open access, points out that a good way of combatting the pseudo-science of Intelligent Design is to make more of the real stuff available through open access.
The piece forms Eisen's first posting to his Open Science blog, which should be well-worth following.
The piece forms Eisen's first posting to his Open Science blog, which should be well-worth following.
22 December 2005
Microsoft: Same as It Ever Was
So Microsoft is up to its old, foxy tricks.
The European Commission is threatening the company with daily fines of "up to" two million Euros. Leaving aside the fact that "up to" includes small numbers like ten, even if Microsoft were fined the maximum amount every day, its huge cash mountain means it could happily tell the Commission to take a running jump for several decades at least.
Of course, it won't come to that. By refusing to comply with the Commission's requests, Microsoft is playing its usual game of chicken. If it wins, its gets away scot-free; but even if it loses, it can still get everything it needs.
The reason for this can be found at the end of the document linked to above. Microsoft is (cunningly) digging its feet in over the first of two issues: "complete and accurate interface documentation". The second issues concerns "the obligation for Microsoft to make the interoperability information available on reasonable terms" as the Commission press release puts it.
The giveaway here is the phrase "on reasonable terms". Back in 2001, the very guardian of the Web, the World Wide Web Consortium, proposed adopting a new patent policy framework that would allow its recommendations to be implemented using "reasonably and non-discriminatory" (RAND) licensing terms. However, as people soon pointed out, this would effectively lock out open source implementations, since RAND terms might easily be incompatible with popular licences (notably the GPL, the cornerstone of the free software world).
After a fairly bloody fight within the cyber corridors of power, good sense prevailed, and the final recommendation came down squarely in favour of royalty-free licensing: "The goal of this policy is to assure that Recommendations produced under this policy can be implemented on a Royalty-Free (RF) basis."
So all Microsoft has to do to stymie its greatest rival - open source software - is to accede to the European Commission's request and graciously adopt "reasonable terms" for access to its interfaces - reasonable, non-discrimatory and completely incompatible with free software licences.
The European Commission is threatening the company with daily fines of "up to" two million Euros. Leaving aside the fact that "up to" includes small numbers like ten, even if Microsoft were fined the maximum amount every day, its huge cash mountain means it could happily tell the Commission to take a running jump for several decades at least.
Of course, it won't come to that. By refusing to comply with the Commission's requests, Microsoft is playing its usual game of chicken. If it wins, its gets away scot-free; but even if it loses, it can still get everything it needs.
The reason for this can be found at the end of the document linked to above. Microsoft is (cunningly) digging its feet in over the first of two issues: "complete and accurate interface documentation". The second issues concerns "the obligation for Microsoft to make the interoperability information available on reasonable terms" as the Commission press release puts it.
The giveaway here is the phrase "on reasonable terms". Back in 2001, the very guardian of the Web, the World Wide Web Consortium, proposed adopting a new patent policy framework that would allow its recommendations to be implemented using "reasonably and non-discriminatory" (RAND) licensing terms. However, as people soon pointed out, this would effectively lock out open source implementations, since RAND terms might easily be incompatible with popular licences (notably the GPL, the cornerstone of the free software world).
After a fairly bloody fight within the cyber corridors of power, good sense prevailed, and the final recommendation came down squarely in favour of royalty-free licensing: "The goal of this policy is to assure that Recommendations produced under this policy can be implemented on a Royalty-Free (RF) basis."
So all Microsoft has to do to stymie its greatest rival - open source software - is to accede to the European Commission's request and graciously adopt "reasonable terms" for access to its interfaces - reasonable, non-discrimatory and completely incompatible with free software licences.
One Door Closes, Another Door Opens
Tomorrow is the end of an era - though you might be forgiven if you failed to notice. Back in July, IBM announced that it was ending support for its OS/2 operating system.
Now, for younger readers, this may not mean much: after all, few today use OS/2. But once upon a time, OS/2 was the Great White Hope - not just for IBM, but apparently for Microsoft too. Both positioned it as the "serious" version of Windows, which was merely a kind of mickey-mouse entry-level system. Of course, it didn't quite work out that way.
What's amazing is not so much that Microsoft managed to outwit IBM (again - after doing it for the first time with MS-DOS), but that IBM stuck with its poor old OS/2 for so long. What's also interesting - and yet another straw in the wind - is that in its migration page, IBM suggests GNU/Linux as the most natural successor.
But it is much more than merely a make-do substitute. OS/2 being closed, dies tomorrow. The open GNU/Linux can never die (though it might go into hibernation). A similar observation was made by this perceptive story on lwn.net in the context of browsers, rather than operating systems.
Now, for younger readers, this may not mean much: after all, few today use OS/2. But once upon a time, OS/2 was the Great White Hope - not just for IBM, but apparently for Microsoft too. Both positioned it as the "serious" version of Windows, which was merely a kind of mickey-mouse entry-level system. Of course, it didn't quite work out that way.
What's amazing is not so much that Microsoft managed to outwit IBM (again - after doing it for the first time with MS-DOS), but that IBM stuck with its poor old OS/2 for so long. What's also interesting - and yet another straw in the wind - is that in its migration page, IBM suggests GNU/Linux as the most natural successor.
But it is much more than merely a make-do substitute. OS/2 being closed, dies tomorrow. The open GNU/Linux can never die (though it might go into hibernation). A similar observation was made by this perceptive story on lwn.net in the context of browsers, rather than operating systems.
21 December 2005
Intelligent Design ... and Bioinformatics
If you are interested in the background to the recent ruling against the teaching of Intelligent Design alongside Darwinian evolution in science classes, you might want to read a fine article on the subject, which also includes the judge's splendidly wise and perceptive remarks.
Of course, it is sad that the case even needed to be made. The idea that Intelligent Design - which essentially asserts that everything is as it is because, er, everything was made that way - can even be mentioned in the same breath as Darwinian evolution is risible. Not because the latter is sancrosanct, and cast-iron truth. But Darwin's theory is a scientific theory, testable and tested. So far, it seems to be a good explanation of the facts. Intelligent Design is simply a restatement of the problem.
Among those facts are the growing number of sequenced genomes. It has always struck me that DNA and bioinformatic analyses of it provide perhaps the strongest evidence for evolution. After all, it is possible to bung a few genomes into a computer, tell it to use some standard mathematical techniques for spotting similarities between abstract data, and out pops what are called phylogenetic trees. These show the likely interrelationships between the genomes. They are not proof of evolution, but the fact that they are generated without direct human intervention (aside from the algorithms employed) is strong evidence in its favour.
One of the most popular ways of producing such trees is to use maximum parsimony. This is essentially an application of Occam's Razor, and prefers simple to complicated solutions.
I'm a big fan of Occam's Razor: it provides another reason why Darwin's theory of natural selection is to be preferred over Intelligent Design. For the former is essentially basic maths applied to organisms: anything that tends to favour the survival of a variant (induced by random variations in the genome) is mathematically more likely to be propagated.
This fact alone overcomes the standard objection that Intelligent Design has to Darwinian evolution: that purely "random" changes could never produce complexity on the time-scales we see. True, but natural selection means that the changes are not purely random: at each stage mathematical laws "pick" those that add to previous advances. In this way, simple light-sensitive cells become eyes, because the advantage of being able to detect light just gets greater the more refined the detection available. Mutations that offer that refinement are preferred, and go forward for further mutations and refinement.
It's the same for Intelligent Design's problem with protein folding. When proteins are produced within the cell from the DNA that codes for them, they are linear strings of amino acids; to become the cellular engines that drive life they must fold up in exactly the right way. It is easy to show that random fluctuations would require far longer than the age of the universe to achieve the correct folding. But the fluctuations are not completely random: at each point there is a move that reduces the overall energy of the protein more than others. Putting together these moves creates a well-defined path towards to folded protein that requires only fractions of a second to traverse.
Of course, it is sad that the case even needed to be made. The idea that Intelligent Design - which essentially asserts that everything is as it is because, er, everything was made that way - can even be mentioned in the same breath as Darwinian evolution is risible. Not because the latter is sancrosanct, and cast-iron truth. But Darwin's theory is a scientific theory, testable and tested. So far, it seems to be a good explanation of the facts. Intelligent Design is simply a restatement of the problem.
Among those facts are the growing number of sequenced genomes. It has always struck me that DNA and bioinformatic analyses of it provide perhaps the strongest evidence for evolution. After all, it is possible to bung a few genomes into a computer, tell it to use some standard mathematical techniques for spotting similarities between abstract data, and out pops what are called phylogenetic trees. These show the likely interrelationships between the genomes. They are not proof of evolution, but the fact that they are generated without direct human intervention (aside from the algorithms employed) is strong evidence in its favour.
One of the most popular ways of producing such trees is to use maximum parsimony. This is essentially an application of Occam's Razor, and prefers simple to complicated solutions.
I'm a big fan of Occam's Razor: it provides another reason why Darwin's theory of natural selection is to be preferred over Intelligent Design. For the former is essentially basic maths applied to organisms: anything that tends to favour the survival of a variant (induced by random variations in the genome) is mathematically more likely to be propagated.
This fact alone overcomes the standard objection that Intelligent Design has to Darwinian evolution: that purely "random" changes could never produce complexity on the time-scales we see. True, but natural selection means that the changes are not purely random: at each stage mathematical laws "pick" those that add to previous advances. In this way, simple light-sensitive cells become eyes, because the advantage of being able to detect light just gets greater the more refined the detection available. Mutations that offer that refinement are preferred, and go forward for further mutations and refinement.
It's the same for Intelligent Design's problem with protein folding. When proteins are produced within the cell from the DNA that codes for them, they are linear strings of amino acids; to become the cellular engines that drive life they must fold up in exactly the right way. It is easy to show that random fluctuations would require far longer than the age of the universe to achieve the correct folding. But the fluctuations are not completely random: at each point there is a move that reduces the overall energy of the protein more than others. Putting together these moves creates a well-defined path towards to folded protein that requires only fractions of a second to traverse.
The IP Penny Begins to Drop
The news that 12 US universities have adopted a series of guiding principles to facilitate collaborative research on open source software really shouldn't be news. The principles simply state that to accerate work in this area, intellectual property (IP) created by such collaborations should be made freely available for use in open source projects. Pretty obvious really: no free sharing, no free software.
But what is interesting about this (aside from the fact that it even needing stating) is the way that it throws up the stark opposition between IP and open source: they simply do not mix. As a consequence, the continuing (and ineluctable) rise of free software means that IP will be increasingly under attack, and shown for what it really is: a greedy attempt to enclose the intellectual commons.
But what is interesting about this (aside from the fact that it even needing stating) is the way that it throws up the stark opposition between IP and open source: they simply do not mix. As a consequence, the continuing (and ineluctable) rise of free software means that IP will be increasingly under attack, and shown for what it really is: a greedy attempt to enclose the intellectual commons.
19 December 2005
Will Wikipedia Fork?
That's the first thought that sprung to my mind when I read that something called rather grandly Digital Universe is to be launched early next year.
Digital Universe is of interest for two reasons. First, it seems to be a kind Wikipedia plus vetting - precisely the kind of thing many have been calling for in the wake of Wikipedia's recent contretemps. The other reason the move is worth noting is that one of the people behind Digital Universe is Larry Sanger, who is usually described as the co-founder of Wikipedia, though the other co-founder, Jimmy Wales, seems to dispute this.
Sanger left Wikipedia in part, apparently, because he was unhappy with the wiki way of working and its results. Digital Universe is not a wiki, so from next year it should be possible to compare two very different approaches to generating large-scale bodies of knowledge from public input.
This is what made me wonder about whether we might see some kind of Wikipedia fork - which is where software development splits into two camps that go their separate ways. There must be many within the Wikipedia community who would prefer something a little more structured than the current Wikipedia: the question is, Will they now jump ship and help build up Digital Universe, or will the latter simply recapitulate the history of Nupedia, Wikipedia's long-forgotten predecessor?
Digital Universe is of interest for two reasons. First, it seems to be a kind Wikipedia plus vetting - precisely the kind of thing many have been calling for in the wake of Wikipedia's recent contretemps. The other reason the move is worth noting is that one of the people behind Digital Universe is Larry Sanger, who is usually described as the co-founder of Wikipedia, though the other co-founder, Jimmy Wales, seems to dispute this.
Sanger left Wikipedia in part, apparently, because he was unhappy with the wiki way of working and its results. Digital Universe is not a wiki, so from next year it should be possible to compare two very different approaches to generating large-scale bodies of knowledge from public input.
This is what made me wonder about whether we might see some kind of Wikipedia fork - which is where software development splits into two camps that go their separate ways. There must be many within the Wikipedia community who would prefer something a little more structured than the current Wikipedia: the question is, Will they now jump ship and help build up Digital Universe, or will the latter simply recapitulate the history of Nupedia, Wikipedia's long-forgotten predecessor?
And Here Is The (Open) News...
The BBC has unveiled its long-awaited Open News Archive. Actually, it's made some 80 news reports available - not quite an "open news archive". But to be fair, it's a start, and potentially the beginning of something quite bold.
There are plenty of restrictions, including the fact that the content is only available to Internet users within the UK. But as the BBC itself says, this is just a pilot. Moreover, the issues that need resolving - notably those to do with "rights clearance" - are by no means trivial. Kudos to the BBC for at least trying. Like the open access book project reported below, this is yet another indication of which way the (open) wind is blowing....
There are plenty of restrictions, including the fact that the content is only available to Internet users within the UK. But as the BBC itself says, this is just a pilot. Moreover, the issues that need resolving - notably those to do with "rights clearance" - are by no means trivial. Kudos to the BBC for at least trying. Like the open access book project reported below, this is yet another indication of which way the (open) wind is blowing....
Open Access: Books Too
Hitherto, open access has tended to refer to scholarly papers published in journals. This makes the idea of establishing an online "press" devoted to book-length titles particularly interesting.
Of course, online pagination has no real meaning (except in terms of convenient layout), so "long" books are just as easy to produce as "short" papers. In this sense, there's nothing new here. But the move is nonetheless important; let's hope it gain momentum.
Of course, online pagination has no real meaning (except in terms of convenient layout), so "long" books are just as easy to produce as "short" papers. In this sense, there's nothing new here. But the move is nonetheless important; let's hope it gain momentum.
18 December 2005
Wellcome Moves
The news that the Wellcome Trust has reached an agreement with three publishers of scientific journals to allow Wellcome-funded research published in their journals to be immediately available online and without charge to the reader is good news indeed.
Good because it will make large quantities of high-quality research immediately available, rather than after the tiresome six-month wait that some journals impose when providing a kind of pseudo-open access. Good, because it shows that the Wellcome Trust is willing to put its money where its mouth is, and to pay to get open access. Good, because by making this agreement with Blackwell, OUP and Springer, the Wellcome Trust puts pressure on the the top science publisher, Elsevier, to follow suit.
In fact, thinking about it, I was probably unkind to describe Nature as the Microsoft of the science world: that honour clearly belongs to Elsevier, both in terms of its power and resistance to opening up. Moreover, Nature, to its credit, now gets it about Wikipedia - it even made subscriber-only content freely available. And the conceptual distance between wikis and open access is surprisingly small; so maybe we're seeing the start of a historic shift at Nature.
Good because it will make large quantities of high-quality research immediately available, rather than after the tiresome six-month wait that some journals impose when providing a kind of pseudo-open access. Good, because it shows that the Wellcome Trust is willing to put its money where its mouth is, and to pay to get open access. Good, because by making this agreement with Blackwell, OUP and Springer, the Wellcome Trust puts pressure on the the top science publisher, Elsevier, to follow suit.
In fact, thinking about it, I was probably unkind to describe Nature as the Microsoft of the science world: that honour clearly belongs to Elsevier, both in terms of its power and resistance to opening up. Moreover, Nature, to its credit, now gets it about Wikipedia - it even made subscriber-only content freely available. And the conceptual distance between wikis and open access is surprisingly small; so maybe we're seeing the start of a historic shift at Nature.
Blogging Avant la Lettre
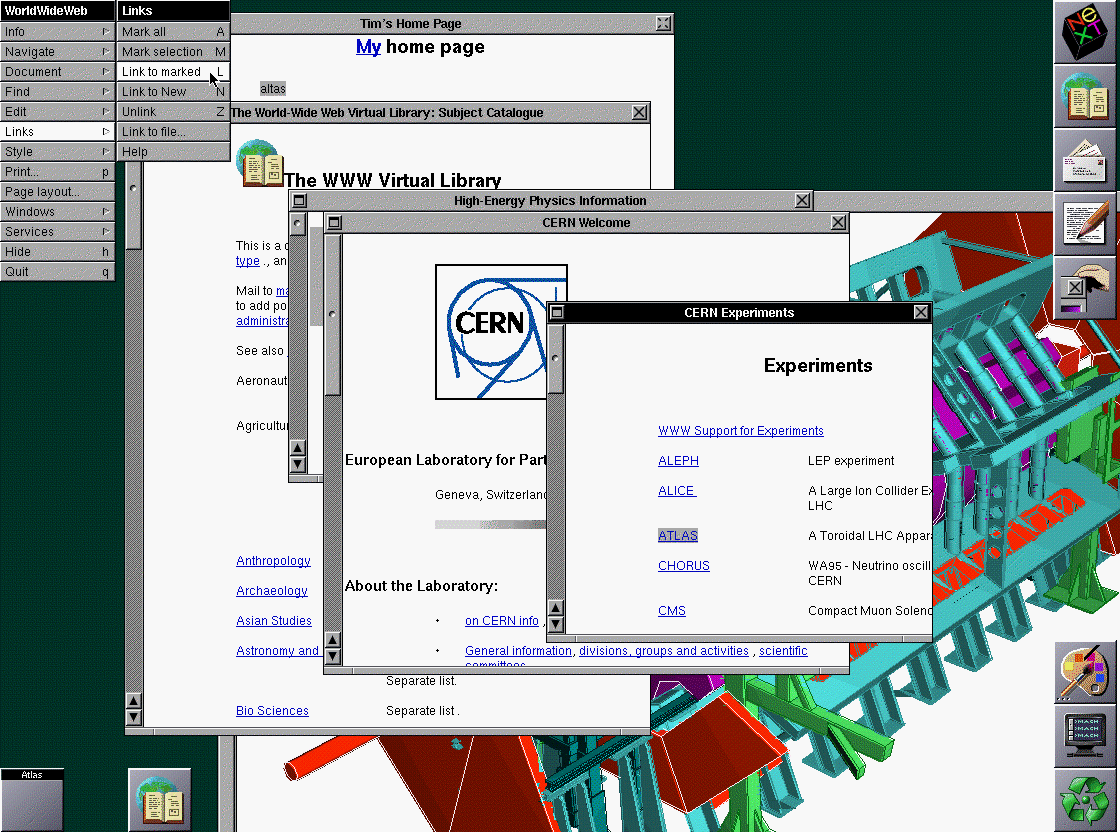
As I have written elsewhere, blogging is as old as the Web itself. In fact, as a perceptive comment on that page remarks, the first blog was written by none other than Tim Berners-Lee.
This makes the recent posting of (Sir) Tim's first official blog entry deeply ironic. Of course, this is not lost on the man himself, and he gently points out that the first browser, called confusingly WorldWideWeb, was fully able to write as well as read Web pages. In other words, it was a blogging tool as much as a browser.
The otherwise amusing sight of Sir Tim re-joining something he'd invented a decade and a half ago is indicative of a rather more worrying fact: that the organisation he heads, the World Wide Web Consortium (which at least managed to snag one of the coolest URLs for its own), is almost unknown today outside the immediate circle of Webheads.
This shows how marginalised it has become, since originally it was set up to provide technical oversight of the Web's development. But it suffered badly during the browser wars, when both Netscape and Micosoft pretty much ignored, and went on adding non-standard elements to their browsers in an attempt to gain the upper hand. Indeed, it is only now, thanks largely to the rise of Firefox, that W3C standards are finally becoming not just widespread, but accepted as real standards.
Nonetheless, the W3C still has much work to do if it is to succeed in moving back to the centre of today's Web. As proof, consider that fact that a W3C document with a title as ell-embracing as "Architecture of the World Wide Web, Volume One" caused nary a ripple on the surface of the Great Cyberpond. Let's hope that Sir Tim's blog will help the sterling work of the W3C to reach a wider audience.
This makes the recent posting of (Sir) Tim's first official blog entry deeply ironic. Of course, this is not lost on the man himself, and he gently points out that the first browser, called confusingly WorldWideWeb, was fully able to write as well as read Web pages. In other words, it was a blogging tool as much as a browser.
{kind=link}
The otherwise amusing sight of Sir Tim re-joining something he'd invented a decade and a half ago is indicative of a rather more worrying fact: that the organisation he heads, the World Wide Web Consortium (which at least managed to snag one of the coolest URLs for its own), is almost unknown today outside the immediate circle of Webheads.
This shows how marginalised it has become, since originally it was set up to provide technical oversight of the Web's development. But it suffered badly during the browser wars, when both Netscape and Micosoft pretty much ignored, and went on adding non-standard elements to their browsers in an attempt to gain the upper hand. Indeed, it is only now, thanks largely to the rise of Firefox, that W3C standards are finally becoming not just widespread, but accepted as real standards.
Nonetheless, the W3C still has much work to do if it is to succeed in moving back to the centre of today's Web. As proof, consider that fact that a W3C document with a title as ell-embracing as "Architecture of the World Wide Web, Volume One" caused nary a ripple on the surface of the Great Cyberpond. Let's hope that Sir Tim's blog will help the sterling work of the W3C to reach a wider audience.
15 December 2005
Open Access - Get the Facts
A piece that writes very positively about open access's future quotes a survey from the Centre for Information Behaviour and the Evaluation of Research (CIBER) that examined academics' attitude to different forms of publishing. According to figures given in a story referred to by the first article, some 96.2% of those surveyed support peer review - the standard academic process whereby a paper is sent to referees for comments on its accuracy. So far, so good.
Except that the headline given on the second site is "Academic authors favour peer review over open access" - as if the two were in opposition. In fact, most open access titles employ peer review, so the 96.2% in favour of it were not expressing any opinion about open access, just about peer review.
However, the second article does quote two other figures: that "nearly half" of the academics surveyed thought that open access would undermine the current system (which requires academic institutions to take out often hugely-expensive subscriptions to journals), and that 41% thought that this was a good thing.
To find out whether this 41% refers to the entire sample, or only to those who thought open access would undermine the old system, I naturally went to the CIBER site in order to find out what the real figures were. It turns out that the 41% refers to the whole sample, not just those who viewed the rise of open access as likely. Among the latter group, more than half were in favour.
The Publishers Association and the International Association of STM Publishers, which sponsored the report, must be pretty gutted by the results that a significant proportion of academics rather like the idea of open access destroying the current system. But not peer review. As Microsoft likes to say, in a rather different context, and with a rather different effect, Get The Facts.
Except that the headline given on the second site is "Academic authors favour peer review over open access" - as if the two were in opposition. In fact, most open access titles employ peer review, so the 96.2% in favour of it were not expressing any opinion about open access, just about peer review.
However, the second article does quote two other figures: that "nearly half" of the academics surveyed thought that open access would undermine the current system (which requires academic institutions to take out often hugely-expensive subscriptions to journals), and that 41% thought that this was a good thing.
To find out whether this 41% refers to the entire sample, or only to those who thought open access would undermine the old system, I naturally went to the CIBER site in order to find out what the real figures were. It turns out that the 41% refers to the whole sample, not just those who viewed the rise of open access as likely. Among the latter group, more than half were in favour.
The Publishers Association and the International Association of STM Publishers, which sponsored the report, must be pretty gutted by the results that a significant proportion of academics rather like the idea of open access destroying the current system. But not peer review. As Microsoft likes to say, in a rather different context, and with a rather different effect, Get The Facts.
13 December 2005
Is KDE Winning?
Wow. Linus "my name is Linus and I am your god" Torvalds has spoken - and the answer is KDE.
If you haven't been following the great war between GNOME and KDE - and frankly, if you haven't, you probably made a wise decision - over what the face of GNU/Linux will be on the desktop, this news may not mean much. After all, Linus is just one voice, right?
Well, no: Linus is *the* voice when it comes to the Linux kernel, and his views carry enormous weight within the free software world. For this reason, he has always assiduously avoided coming down on one side of the other regarding desktop interfaces - until now.
As well as this flat-out endorsement from the man himself, there are other straws in the wind that suggest that KDE may emerge as the preferred desktop environment. For example, the amazing Knoppix live CD system, which has spawned dozens of other live CD systems, has always opted for KDE. More recently, the increasingly popular Ubuntu GNU/Linux distribution, which uses GNOME, has appeared in an KDE incarnation known as Kubuntu, and received the blessing of He Who Is Known As The SABDFL.
The reason this all matters is that 2006 may well prove the year that GNU/Linux makes its big breakthrough on the desktop. Just like 2005 and 2004.
If you haven't been following the great war between GNOME and KDE - and frankly, if you haven't, you probably made a wise decision - over what the face of GNU/Linux will be on the desktop, this news may not mean much. After all, Linus is just one voice, right?
Well, no: Linus is *the* voice when it comes to the Linux kernel, and his views carry enormous weight within the free software world. For this reason, he has always assiduously avoided coming down on one side of the other regarding desktop interfaces - until now.
As well as this flat-out endorsement from the man himself, there are other straws in the wind that suggest that KDE may emerge as the preferred desktop environment. For example, the amazing Knoppix live CD system, which has spawned dozens of other live CD systems, has always opted for KDE. More recently, the increasingly popular Ubuntu GNU/Linux distribution, which uses GNOME, has appeared in an KDE incarnation known as Kubuntu, and received the blessing of He Who Is Known As The SABDFL.
The reason this all matters is that 2006 may well prove the year that GNU/Linux makes its big breakthrough on the desktop. Just like 2005 and 2004.
Closing the Web
For a long time, I have had two great Web hates: pages made up of PDFs and those using Flash animations. I realise now that to these I have to add a third, and for the same reason: they all undermine the openness and transparency that underlie the Web's enormous power.
I hate PDFs because they are opaque compared to Web pages. With the latter, you can see the underlying code and get at (in programming terms) individual elements of the page. This is important if you want to do clever Web 2.0-y things with content, such as mixing and matching (and mashing).
I hate Flash animations even more: they are not only opaque - there is no cyber-there there - they are barriers to my free navigation of the Web and waste my time as they download. In effect, they turn the Web into television.
To these, I must now add TinyURLs. In themselves, they are a great idea: too many Internet addresses have become long snaking strings of apparently random text. But the solution - to replace this with a unique but shorter URL beginning http://tinyurl.com commits the sin of obscuring the address, an essential component of the open Web.
So while I applaud TinyURL's rigorous terms of use, I never follow any TinyURLs in my Web wanderings, however easy and seductive they might be. For all I know, they might well be taking me straight to a PDF or Flash animation.
I hate PDFs because they are opaque compared to Web pages. With the latter, you can see the underlying code and get at (in programming terms) individual elements of the page. This is important if you want to do clever Web 2.0-y things with content, such as mixing and matching (and mashing).
I hate Flash animations even more: they are not only opaque - there is no cyber-there there - they are barriers to my free navigation of the Web and waste my time as they download. In effect, they turn the Web into television.
To these, I must now add TinyURLs. In themselves, they are a great idea: too many Internet addresses have become long snaking strings of apparently random text. But the solution - to replace this with a unique but shorter URL beginning http://tinyurl.com commits the sin of obscuring the address, an essential component of the open Web.
So while I applaud TinyURL's rigorous terms of use, I never follow any TinyURLs in my Web wanderings, however easy and seductive they might be. For all I know, they might well be taking me straight to a PDF or Flash animation.
Driving Hard
Hard discs are the real engines of the computer revolution. More than rising processing speeds, it is constantly expanding hard disc capacity that has made most of the exciting recent developments possible.
This is most obvious in the case of Google, which now not only searches most of the Web, and stores its (presumably vast) index on cheap hard discs, but also offers a couple of Gbytes of storage to everyone who uses/will use its Gmail. Greatly increased storage has also driven the MP3 revolution. The cheap availability of Gigabytes of storage means that people can - and so do - store thousands of songs, and now routinely expect to have every song they want on tap, instantly.
Yet another milestone was reached recently, when even the Terabyte (=1,000 Gbytes) became a relatively cheap option. For most of us mere mortals, it is hard to grasp what this kind of storage will mean in practice. One person who has spent a lot of time thinking hard about such large-scale storage and what it means is Jim Gray, whom I had the pleasure of interviewing last year.
On his Web site (at Microsoft Research), he links to a fascinating paper by Michael Lesk that asks the question How much information is there in the world? (There is also a more up-to-date version available.) It is clear from the general estimates that we are fast approaching the day when it will be possible to have just about every piece of data (text, audio, video) that relates to us throughout our lives and to our immediate (and maybe not-so-immediate) world, all stored, indexed and cross-referenced on a hard disc somewhere.
Google and the other search engines already gives us a glimpse of this "Information At Your Fingertips" (now where did I hear that phrase before?), but such all-encompassing Exabytes (1,000,000 Terabytes) go well beyond this.
What is interesting is how intimately this scaling process is related to the opening up of data. In fact, this kind of super-scaling, which takes us to realms several orders of magnitude beyond even the largest proprietary holdings of information, only makes sense if data is freely available for cross-referencing (something that cannot happen if there are isolated bastions of information, each with its own gatekeeper).
Once again, technological developments that have been in train for decades are pushing us inexorably towards an open future - whatever the current information monopolists might want or do.
This is most obvious in the case of Google, which now not only searches most of the Web, and stores its (presumably vast) index on cheap hard discs, but also offers a couple of Gbytes of storage to everyone who uses/will use its Gmail. Greatly increased storage has also driven the MP3 revolution. The cheap availability of Gigabytes of storage means that people can - and so do - store thousands of songs, and now routinely expect to have every song they want on tap, instantly.
Yet another milestone was reached recently, when even the Terabyte (=1,000 Gbytes) became a relatively cheap option. For most of us mere mortals, it is hard to grasp what this kind of storage will mean in practice. One person who has spent a lot of time thinking hard about such large-scale storage and what it means is Jim Gray, whom I had the pleasure of interviewing last year.
On his Web site (at Microsoft Research), he links to a fascinating paper by Michael Lesk that asks the question How much information is there in the world? (There is also a more up-to-date version available.) It is clear from the general estimates that we are fast approaching the day when it will be possible to have just about every piece of data (text, audio, video) that relates to us throughout our lives and to our immediate (and maybe not-so-immediate) world, all stored, indexed and cross-referenced on a hard disc somewhere.
Google and the other search engines already gives us a glimpse of this "Information At Your Fingertips" (now where did I hear that phrase before?), but such all-encompassing Exabytes (1,000,000 Terabytes) go well beyond this.
What is interesting is how intimately this scaling process is related to the opening up of data. In fact, this kind of super-scaling, which takes us to realms several orders of magnitude beyond even the largest proprietary holdings of information, only makes sense if data is freely available for cross-referencing (something that cannot happen if there are isolated bastions of information, each with its own gatekeeper).
Once again, technological developments that have been in train for decades are pushing us inexorably towards an open future - whatever the current information monopolists might want or do.
Publish and Be Damned!
The wilful misunderstanding of Google Books by traditional publishers is truly sad to see. They continue to propagate the idea that Google is somehow going to make the entire text of their titles available, whereas in fact it simply wants to index that text, and make snippets available in its search results.
As a an author I welcome this; nothing makes me happier than see that a search for the phrase "digital code" at Google Books brings up my own title as the top hit. The fact that anyone can dip into the book can only increase sales (assuming the book is worth reading, at least). Yes, it might be possible for a gang of conspirators to obtain scans of the entire book if they had enough members and enough time to waste doing so. But somehow, I think it would be easier to buy the book.
Of course, what is really going on here is a battle for control - as is always the case with open technologies. The old-style publishers are fighting a losing battle against new technologies (and open content) by being as obstructive as possible. Instead, they should be spending their energies working out new business models that let them harness the Internet and search engines to make their books richer and more available to readers.
They are bound to lose: the Internet will continue to add information until it is "good enough" for any given use. This may take time, and the mechanisms for doing so still need some work (just look at Wikipedia), but the amount of useful information is only going in one direction. Traditional publishers will cling on to the few titles that offer something beyond this, but the general public will have learned to turn increasingly to online information that is freely available. More importantly, they will come to expect that free information will be there as a matter of course, and will unlearn the habit of buying expensive stuff printed on dead trees.
It is this dynamic that is driving all of the "opens" - open source, open access, open genomics. The availability of free stuff that slowly but inexorably gets better means that the paid stuff will always be superseded at some point. It happened with the human genome data, when the material made available by the public consortium matched that of Celera's subscription service, which ultimately became irrelevant. It is happening with open source, as GNU/Linux is being swapped in at every level, replacing expensive Unix and Microsoft Windows systems. And it will happen with open content.
As a an author I welcome this; nothing makes me happier than see that a search for the phrase "digital code" at Google Books brings up my own title as the top hit. The fact that anyone can dip into the book can only increase sales (assuming the book is worth reading, at least). Yes, it might be possible for a gang of conspirators to obtain scans of the entire book if they had enough members and enough time to waste doing so. But somehow, I think it would be easier to buy the book.
Of course, what is really going on here is a battle for control - as is always the case with open technologies. The old-style publishers are fighting a losing battle against new technologies (and open content) by being as obstructive as possible. Instead, they should be spending their energies working out new business models that let them harness the Internet and search engines to make their books richer and more available to readers.
They are bound to lose: the Internet will continue to add information until it is "good enough" for any given use. This may take time, and the mechanisms for doing so still need some work (just look at Wikipedia), but the amount of useful information is only going in one direction. Traditional publishers will cling on to the few titles that offer something beyond this, but the general public will have learned to turn increasingly to online information that is freely available. More importantly, they will come to expect that free information will be there as a matter of course, and will unlearn the habit of buying expensive stuff printed on dead trees.
It is this dynamic that is driving all of the "opens" - open source, open access, open genomics. The availability of free stuff that slowly but inexorably gets better means that the paid stuff will always be superseded at some point. It happened with the human genome data, when the material made available by the public consortium matched that of Celera's subscription service, which ultimately became irrelevant. It is happening with open source, as GNU/Linux is being swapped in at every level, replacing expensive Unix and Microsoft Windows systems. And it will happen with open content.
12 December 2005
Going to the Dogs
My heart leapt last week upon seeing the latest issue of Nature magazine. The front cover showed the iconic picture of Watson and Crick, with the latter pointing at their model of DNA's double helix. A rather striking addition was the boxer dog next to Crick, also gazing up at the DNA: inside the journal was a report on the first high-quality sequencing of the dog genome (a boxer, naturally).
This is big news. Think of the genome as a set of software modules that form a cell's operating system. Every change to a genome is a hack; like most hacks, most changes cause malfunctions, and the cell crashes (= dies/grows abnormally). Some, though, work, and produce slight variants of the original organism. Over time, these variations can build up to form an entirely new species. (In other words, one way of thinking about evolution is in terms of Nature's hacking).
Mostly, the changes produced by these hacks are small, or so slow as to be practically invisible. But not for dogs. Humans have been hacking the dog genome for longer than any other piece of code - about 100,000 years - and the result can be seen in the huge variety of dog breeds (some 400 0f them).
Getting hold of the dog genome means that scientists have access to this first Great Historical Hack, which will tell us much about how genomic variation translates to different physical traits (known as phenotypes). Even better - for us, though not for the dogs - is that all this hacking/interbreeding has produced dogs that suffer from many of the same diseases as humans. Because particular breeds are susceptible to particular diseases, we know that there must be a strong genetic element to these diseases for dogs, and so, presumably, for humans (since our genomes are so similar). The different breeds have effectively separated out the genes that produce a predisposition to a particular disease, making it far easier to track them down than in the human code.
That tracking down will take place by comparing the genomes for different breeds, and by comparing dog genomes against those of humans, mice, apes and so on. Those comparisons are only possible because all this code is in the public domain. Had the great battle over open genomics - open source genomes - been lost at the time of the Human Genome Project, progress towards locating these genes that predispose towards major diseases would have been slowed immeasurably. Now it's just a matter of a Perl script or two.
Given this open source tradition, and the importance of the dog genome, it's a pity that the Nature paper discussing it is not freely available. Alas, for all its wonderful traditions and historic papers, Nature is still the Microsoft of the science world. The battle for open access - like that for open source - has still to be won.
This is big news. Think of the genome as a set of software modules that form a cell's operating system. Every change to a genome is a hack; like most hacks, most changes cause malfunctions, and the cell crashes (= dies/grows abnormally). Some, though, work, and produce slight variants of the original organism. Over time, these variations can build up to form an entirely new species. (In other words, one way of thinking about evolution is in terms of Nature's hacking).
Mostly, the changes produced by these hacks are small, or so slow as to be practically invisible. But not for dogs. Humans have been hacking the dog genome for longer than any other piece of code - about 100,000 years - and the result can be seen in the huge variety of dog breeds (some 400 0f them).
Getting hold of the dog genome means that scientists have access to this first Great Historical Hack, which will tell us much about how genomic variation translates to different physical traits (known as phenotypes). Even better - for us, though not for the dogs - is that all this hacking/interbreeding has produced dogs that suffer from many of the same diseases as humans. Because particular breeds are susceptible to particular diseases, we know that there must be a strong genetic element to these diseases for dogs, and so, presumably, for humans (since our genomes are so similar). The different breeds have effectively separated out the genes that produce a predisposition to a particular disease, making it far easier to track them down than in the human code.
That tracking down will take place by comparing the genomes for different breeds, and by comparing dog genomes against those of humans, mice, apes and so on. Those comparisons are only possible because all this code is in the public domain. Had the great battle over open genomics - open source genomes - been lost at the time of the Human Genome Project, progress towards locating these genes that predispose towards major diseases would have been slowed immeasurably. Now it's just a matter of a Perl script or two.
Given this open source tradition, and the importance of the dog genome, it's a pity that the Nature paper discussing it is not freely available. Alas, for all its wonderful traditions and historic papers, Nature is still the Microsoft of the science world. The battle for open access - like that for open source - has still to be won.
Yahoo! Gets Del.icio.us
The only suprising thing about Yahoo's acquisition of del.icio.us is that Yahoo got there before Google.
The three-way battle between Microsoft, Google and Yahoo for dominance hinges on who can colonise the Web 2.0 space first. Google seemed to be ahead, with its steady roll-out of services like Gmail (albeit in beta) and purchase of Blogger and Picasa. But Yahoo is coming on strongly: now that it has both Flickr and del.icio.us it has started to catch up fast.
The dark horse, as ever is Microsoft: its recent announcement of Windows and Office Live show that it does not intend to be left behind. But unlike its previous spurts to overtake early leaders like Netscape, this one requires something more profound than mere technical savvy or marketing might.
Web 2.0 has at its heart sharing and openness (think blogs, Flickr, del.icio.us etc.). For Microsoft to succeed, it needs to embrace a philosophy which is essentially antithetical to everything it has done in its history. Bill Gates is a brilliant manager, and he has many thousands of very clever people working for him, but this may not be enough. Even as it tries to demonstrate "openness" - through SharedSource, or "opening" its Office XML formats - the limits of Microsoft's ability fully to embrace openness become clearer. But that is the point about being real open: it is all or nothing.
The question is not so much whether Microsoft will ever get it - everything in its corporate DNA says it won't - but whether Google and Yahoo will. In this sense, Web 2.0 is theirs to lose, rather than for Microsoft to win.
The three-way battle between Microsoft, Google and Yahoo for dominance hinges on who can colonise the Web 2.0 space first. Google seemed to be ahead, with its steady roll-out of services like Gmail (albeit in beta) and purchase of Blogger and Picasa. But Yahoo is coming on strongly: now that it has both Flickr and del.icio.us it has started to catch up fast.
The dark horse, as ever is Microsoft: its recent announcement of Windows and Office Live show that it does not intend to be left behind. But unlike its previous spurts to overtake early leaders like Netscape, this one requires something more profound than mere technical savvy or marketing might.
Web 2.0 has at its heart sharing and openness (think blogs, Flickr, del.icio.us etc.). For Microsoft to succeed, it needs to embrace a philosophy which is essentially antithetical to everything it has done in its history. Bill Gates is a brilliant manager, and he has many thousands of very clever people working for him, but this may not be enough. Even as it tries to demonstrate "openness" - through SharedSource, or "opening" its Office XML formats - the limits of Microsoft's ability fully to embrace openness become clearer. But that is the point about being real open: it is all or nothing.
The question is not so much whether Microsoft will ever get it - everything in its corporate DNA says it won't - but whether Google and Yahoo will. In this sense, Web 2.0 is theirs to lose, rather than for Microsoft to win.
...and Went Down to the Sea
"Open": it's such a small word (and a strange one at that: stare at it long enough and it begins to look like something from another tongue). It's much used, and very abused these days. But that's to be expected, since it's fast becoming where so many other currents and trends are heading. Everyone, it seems, wants to be open.
That's what these pages are all about: how "openness" - as manifested in open source, open genomics, open content and all the other opens – lies at the heart of most of what's interesting in technology today. And not only. Just as technology is making its presence felt in so many other areas of life, so the open movements and their philosophies are feeding through there, too.